Jacques Baudron – secrétaire Forum ATENA – mai 2024
Peut-être vous sentez-vous en sécurité : vos données sont sous la protection du RGPD.
Sauf que le RGPD ne s’applique qu’aux données où votre nom apparait mais pas aux données anonymisées. Problème : une quinzaine d’informations suffisent à lever l’anonymat, seuil rapidement atteint par la moindre navigation sur internet, la seule fréquentation d’un centre médical ou simple ravitaillement dans un supermarché.
Je vous propose de retrouver les failles de l’anonymat dans ce papier publié il y a trois ans mais toujours d’actualité …
———
L’Europe s’est dotée d’un efficace outil de protection des données personnelles, le RGPD.
Cela dit, l’outil limite lui-même son domaine d’utilisation aux données non anonymes. Les données anonymes ne sont pas concernées et peuvent circuler librement. Un problème majeur se profile : l’anonymat résistera-t-il à l’analyse des (méta) données ?
La réponse est négative. Anonymat (effacement des données identifiantes) et pseudonymat (substitution des noms) sont tous deux concernés. Reportons-nous aux travaux réalisés par Yves-Alexandre de Montjoye et l’Université Catholique de Louvain pour éclairer l’affirmation.
Anonymat et pseudonymat
L’anonymat supprime les données qui permettraient d’isoler un individu dans un jeu de données, de relier entre elles des données indépendantes relatives à un même individu ou de déduire de nouvelles informations sur un individu.
Le pseudonymat remplace les données identifiantes par des alias.
Anonymiser ou pseudonymiser permettent de ne pas se soumettre au RGPD.
Pour une poignée d’attributs
Dès 2013, Yves-Alexandre de Montjoye malmène le sentiment de sécurité apporté par l’anonymat. Nos habitudes de déplacement avec un téléphone portable laissent des traces aussi lisibles qu’une empreinte digitale. En bornant un mobile une fois par heure, quatre points suffisent pour identifier de manière unique 95 % au sein d’une population d’abonnés d’un million et demi d’abonnés.
Si de plus vous appelez régulièrement votre conjoint à midi, vous regardez la météo en attendant le bus ou si le niveau de votre batterie est régulièrement déchargée en fin de journée, vous vous approchez de l’unicité. Le moindre clic sur un bouton « J’aime » affine l’identification.
Application pratique bienvenue : c’est grâce à ces techniques qu’a pu être dressée une cartographie des victimes du tremblement de terre au Népal en 2015. Les données mobiles renseignent sur les populations, l’usage du téléphone trahit le sexe. Le tout fut d’un grand profit dans la gestion des moyens de secours.
En 2021, ses équipes nous proposent un outil pour tester notre unicité : une poignée d’informations (région, date de naissance, niveau d’étude, sexe, situation maritale) suffit à vous cerner. On calcule le nombre d’individus dans la population totale qui partagent les mêmes attributs : le résultat varie de quelques dizaines à … un.
La précision augmente rapidement avec le nombre de paramètres ainsi qu’on peut le voir sur le graphique ci-dessous extrait de l’article de Nature du 23 juillet 2019 sur l’étude de la probabilité de succès d’une tentative de réidentification.
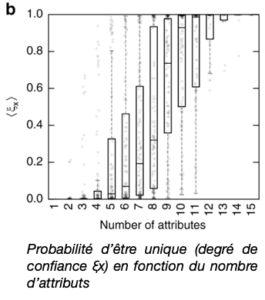
Exemple au Massachusetts : avec le sexe, le code postal et la date de naissance et le nombre d’enfants, 79,4 % de la population peut être identifiée avec un degré de confiance supérieur à 80 %. Avec 15 attributs, 99,98 % de la population est unique.
Le « Data Broker » Experian ne s’y est pas trompé en construisant un tableau de 123 millions de lignes et 248 colonnes. Parlons simplement : une ligne par foyer étasunien (ou presque) et une colonne par attribut. Un attribut est par exemple la composition du foyer, le nombre de voitures, d’animaux, les âges et niveaux d’études, les abonnements télé, salle de sport, journaux, les cartes de fidélité. Nous sommes rapidement au delà des quinze attributs. Experian propose ainsi son fichier à la location. Les utilisateurs sont libres d’utiliser le fichier comme bon leur semble, y compris bien entendu d’accéder aux identités par recoupement.
Anecdote : Alteryx, client d’Experian, a (hooops !) laissé fuiter le fichier pour le plus grand bonheur des agences de publicité, assureurs ou data broker. Ne soyez pas étonnés, la chose est malheureusement courante. D’après https://www.itgovernance.co.uk/data-breaches, près d’une société sur deux est victime d’un vol de données chaque année et chaque jour ou presque une fuite est révélée.
Pour ma part, je préconise de limiter au maximum les informations distribuées aux fournisseurs, les renseignements fournis pour avoir droit à une carte de fidélité, le partage de photos sur des sites publics, l’utilisation de messagerie telles que gmail (relisez les Conditions Générales d’Utilisation au cas où vous les auriez acceptées un peu trop rapidement : vous autorisez Google à lire votre courrier … ). Mais hélas, ne laisser filtrer que peu d’informations personnelles constitue déjà une information structurant.
Et les données de santé ?
Le partage des données de santé en clair et à l’insu des patients entre les hôpitaux et tout partenaire est autorisé depuis 1996.
Rassurez-vous, ce n’est pas pour nous : je fais allusion à la loi Health Insurance Portability and Accountability Act de 1996 (HIPAA) des États-Unis. C’est ce qui a permis à Google de récolter en toute légalité les données de santé pour travailler avec l’organisme de soin Ascension. Ces données n’ont pas besoin d’être anonymisées car elles entrent dans le cadre de “l’échange de données entre les acteurs de la santé”.
En Europe, il en va autrement. Le RGPD établit très rigoureusement les règles de transfert d’informations. Seul un accord explicite de la personne concernée permet le transfert des données non anonymisées ou pseudonymisées..
Sauf que le règlement est de portée limitée : seules les données affichant en clair l’identité des personnes concernées sont concernées. L’effacement des informations qui permettraient de retrouver l’identité permet de ne pas avoir à s’y soumettre. Afin de ne pas entraver les recherches statistiques, il est même possible de conserver toutes les informations dans la mesure où elles ont recours à des alias. Et c’est un sacré « trou dans la raquette ».
Dans ces conditions, retrouver les données manquantes par recoupements est d’autant plus facile que le nombre d’attributs est largement au delà des quinze évoqués plus haut : il se chiffre en milliers. Intuitivement, on comprend qu’un enregistrement indiquant la date de naissance, le sexe, les dates et lieux d’hospitalisation, le détail des traitements et les différents praticiens ne peut pas rester longtemps anonyme.
Le regroupement des données de santé dans une grande base de données ouverte (Health Data Hub) est très dérangeant car il autorise n’importe quelle entreprise même commerciale à y accéder alors que l’anonymat ne saura résister au moindre recoupement. C’est la porte ouverte aux banques, assureurs, employeurs pour sélectionner prospects et candidats à partir des données personnelles. Le HDH appelle largement dans ses pages d’accueil à faire une demande d’accès
Quoique légitime, le combat pour la souveraineté des infrastructures ne nous assure pas une victoire sur la souveraineté des données. Que l’hébergeur soit GAFAMien ou européen, l’accès aux données est aussi facile : qu’importe le fournisseur du coffre fort quand la clef reste sur la serrure. On peut s’interroger sur les limites de l’open data.
Quand nos données sont exploitées par des publicitaires, on est excédé par les messages qui calquent nos recherches. Quand elles sont utilisées par une compagnie d’assurance, on s’étonne d’une tarification élevée. Quand une banque en profite, les taux grimpent inexplicablement. Et quand une candidature d’emploi est écartée, on ne sait pas pourquoi. Mais ce n’est pas forcément la malchance.
Et si par jeu, je laissais ce billet sans signature ?
Jacques Baudron – Secrétaire Forum ATENA – jacques.baudron@ixtel.fr – Septembre 2021



“Sauf que le règlement est de portée limitée : seules les données affichant en clair l’identité des personnes concernées sont concernées.” Ce n’est pas exact, la définition donnée par la CNIL est “Une donnée personnelle est toute information se rapportant à une personne physique identifiée ou identifiable.”. Confirmé par “Article 4 du RGPD «données à caractère personnel», toute information se rapportant à une personne physique identifiée ou identifiable (ci-après dénommée «personne concernée») ; est réputée être une «personne physique identifiable» une personne physique qui peut être identifiée, directement ou indirectement, …;
Pour ce qui concerne “Le regroupement des données de santé dans une grande base de données ouverte (Health Data Hub) est très dérangeant car il autorise n’importe quelle entreprise même commerciale à y accéder…” c’est aussi inexact. Il suffit de consulter les site du HDH : https://www.health-data-hub.fr/utilisateur-de-donnees pour vérifier qu’une entreprise commerciale n’y aura pas accès.
Merci pour votre commentaire éclairé et pertinent.
Je me permets de maintenir que le RGPD ne concerne pas les données anonymisées et que toute entreprise commerciale peut accéder aux données du HDH.
– Anonymat : la CNIL précise que « L’anonymisation n’est qu’une solution parmi d’autres pour pouvoir exploiter des données personnelles dans le respect des droits et libertés des personnes » (https://www.cnil.fr/fr/lanonymisation-des-donnees-un-traitement-cle-pour-lopen-data#:~:text=Le%20règlement%20général%20sur%20la,droits%20et%20libertés%20des%20personnes.)
– Accès des entreprises aux HDH : « L’intérêt public n’est pas, a priori, incompatible avec l’intérêt commercial et la qualité du demandeur n’est pas un critère d’appréciation de l’intérêt public » (https://www.health-data-hub.fr/interet-public)
Ma crainte à l’origine de ce papier est de voir que des banques, assureurs ou employeurs pourraient en toute légalité accéder aux données anonymisées du HDH puis lever l’anonymat.
J’espère que ces précisions apportent un éclairage à mes propos, et je reste bien entendu ouvert à vos commentaires.
Bien cordialement,
Jacques Baudron